
Unix高级编程之signal
signal函数相关的细节描述详见另外两篇篇博客,这里不详细赘述:
https://langzi989.github.io/2017/09/08/C++%E5%87%BD%E6%95%B0%E6%8C%87%E9%92%88%E5%AD%A6%E4%B9%A0/
https://langzi989.github.io/2017/05/04/Wait%E5%87%BD%E6%95%B0%E8%AF%A6%E8%A7%A3/
显示信号的描述
信号的个数可以用宏NSIG获取。
显示信号的描述有三种方法:123456789//first methodchar* strsignal(int sig);//second method,void psignal(int sig, char* msg);//third memthodsys_siglist[sig];
上述三种方法的区别
sys_siglist是直接存储信号描述的数组,一般情况下,推荐使用strsignal。
strsignal和psignal函数对locale敏感,会打印出当地的语言。
调用psignal会在本地的错误出输出流输出,msg:strsignalmsg;
如:12//此时错误数据流将会打印出:SIGINT:Interruptpsignal(SIGINT, "SIGINT");
信号集
许多相关的系统调用涉及到一组不同的信号,这时候需要信号集。linux中使用sigset_t结构体来表示信号集。一般情况,信号集是使用掩码实现的,但是可能有一些是其他实现方式。
信号集结构体相关的函数.123456789101112131415161718192021222324252627282930//初始化空信号集。注意不可使用memset或者静态变量全局变量初始化信号集为空,这样会出问题。因为不是所有的信号集都是通过掩码实现的//0出错,1成功int sigemptyset(sigset_t* set);//初始化信号集包括所有的信号//0出错,1成功int sigfillset(sigset_t* set);//向信号集中添加信号//0出错,1成功int sigaddset(sigset_t* set, int sig);//从信号集中去除信号//0出错,1成功int sigdelset(sigset_t* set, int sig);//检查某一信号是不是在当前信号集中。返回1在,0不在int sigismember(const sigset_t* set, int sig);//以下三个为GNU C中的非标准函数,#define _GNU_SOURCE//对两个信号集作交集存储于dest中int sigandset(sigset_t* dest, sigset_t* left, sigset_t* right);//对两个信号集做并集存储于dest中int sigorset(sigset_t* dest, sigset_t* left, sigset_t* right);//判断信号集是否为空int sigisemptyset(const sigset_t* set);
信号掩码(进程中阻塞信号传递)
内核会为每个进程维护一个信号掩码(标识一组信号),当一个信号被传递到该进程的时候,若该信号在信号掩码中,进程会阻塞该信号的传递,直到将该信号从信号掩码中剔除。
向信号掩码中添加一个信号的方式有以下几种:
- 当调用信号处理器程序的时候,可将引发该调用的信号自动添加到信号掩码中,这取决于sigaction函数在安装信号时使用的标志。
- 使用sigaction函数建立信号处理程序时,可以指定一组额外信号,当调用该处理器程序时将阻塞。
- 使用sigprocmask函数修改进程的信号掩码。
sigprocmask函数
|
|
参数:
- how : 指定修改信号掩码的方式,有三种方式
- SIG_BLOCK : 向指定信号中添加指定信号.
- SIG_UNBLOCK: 将指定信号从原有的信号掩码中移除。若被移除的信号掩码不存在不报错
- SIG_SETMASK: 直接设置(赋值),覆盖原有的值
- set : 需要设置的新的信号掩码集
- old: 旧的信号掩码集。可在设置信号掩码集之后回复原有的信号掩码。
|
|
sigpending获取正在等待状态的信号
若进程接收信号被阻塞之后,我们希望获取被阻塞的信号,则可以使用sigpending函数
|
|
使用此函数的场景是:若某个进程接收到被阻塞的信号,如果希望这些信号被移出阻塞队列,此时可以通过sigpending获取被阻塞的信号,然后将此信号的处理器函数IGNORE,并将其剔除信号掩码即可。
在信号被阻塞的时候,不对信号做排队处理,即即使进程阻塞了100个SIGINT信号,此时当SIGINT从信号掩码中去除时,该进程接收的还是只是一个SIGINT信号。
sigaction函数
除了signal函数之外,sigaction系统调用是设置信号处理的另一个选择。sigaction和signal函数相比更加灵活和具有可移植性。sigaction允许在不改变信号处理器程序的情况下获取信号的默认处理方式。
Unix网络编程之主机字节序与网络字节序
在各种计算机体系中,对于字节,字等的存储机制有所不同,但是在网络通信过程中,如果双方交流的信息存储结构不一致,则会导致通信失败的结果。当前计算机中通常采用的字节存储机制主要有两种:大端规则与小端规则。网络通信的过程中的存储机制统一为大端规则。
字节序
参考:http://www.cppblog.com/tx7do/archive/2015/12/14/71276.html
Unix网络编程基础之套接字结构
大多数的套接字函数都使用到了套接字地址,它们以套接字地址的指针作为参数。每个协议族都定义了自己的套接字地址结构,这些套接字地址结构均以sockaddr_开头,以协议族唯一的后缀结尾。
IPv4套接字地址结构
IPv4的套接字以sockaddr_in命名,其具体定义如下:1234567891011121314struct in_addr { in_addr_t s_addr;};struct sockaddr_in { uint8 sin_len; //套接字的长度,sizeof(struct sockaddr_in) sa_family_t sin_family; //协议族 in_port_t sin_port; //套接字端口 struct in_addr sin_addr; //套接字地址 char sin_zero[8]; //保留位}
- sin_len : 套接字的长度字段,类型为uint8_t,sizeof(struct sockaddr_in),不是所有的系统都支持。长度字段简化了可变长度的套接字的处理。在使用过程中无需设置和检查它,除非涉及路由套接字。
- sin_family : 协议族,IPv4的协议族为AF_INET.类型为无符号整形,其长度受系统的影响。若sockaddr_in中含有sin_len字段,其大小为16位,若含有长度字段,其大小为8位。
- sin_port : 套接字端口, 一般为uint16_t类型。
- sin_addr : 套接字Ip,其类型为in_addr,in_addr中的s_addr类型为uint32_t.
- sin_zero : 不常用,若需要在套接字中加入额外字段,使用到此字段,若不使用将其置为0,一般使用sockaddr_in首先将整个结构置0。
注意:套接字地址结构仅在本机上使用,虽然结构中的某些字段用在不同主机之间的通信,但是结构体本身不在主机之间传递。
协议族参数说明
网络通信过程中有不同的协议族,通常我们在socket地址的sin_family中指出当前通信使用的协议族,不同协议族对应不同的参数,其对应参数如下所示:
| sin_family | 协议说明 |
|---|---|
| AF_INET | IPv4协议 |
| AF_INET6 | IPv6协议 |
| AF_LOCAL | Unix域协议 |
| AF_ROUTE | 路由套接字协议 |
| AF_KEY | 密钥套接字 |
通用套接字地址结构
套接字函数以套接字地址结构指针作为参数的过程中,由于在C中没有继承的机制,这个时候向套接字函数传递参数的时候,由于不同协议的套接字地址不同,会出现问题。这个时候有一种解决办法就是传递void*指针给socket函数,但是void空指针的出现在socket函数之后,所以这个方案不可行。这个时候的解决方案是 定义一个通用的套接字函数,socket函数的参数为通用套接字地址的指针,传递参数的时候我们将特定的套接字指针强制转换为通用套接字地址指针。 如bind函数的函数原型为:1int bind(int, struct sockaddr*, socklen_t);
通用套接字地址的定义如下:
|
|
Ubuntu16.04中sockaddr_in的定义
Ubuntu16.04中sockaddr_in的定义在/usr/include/netinet/in.h,注意其不支持sin_len字段,为了保持与通用套接字字符串兼容,其保留字符串的长度直接用通用套接字的大小减去其他字段。
|
|
Unix时间相关函数总结
在进行Unix编程的过程中,我们不可避免的会遇到需要时间相关的操作,如文件的创建修改时间,数据库中字段插入或更新的时间。
Unix时间相关的类型
- time_t
- struct timeb
- struct timeval
- struct timespec
- struct tm
- clock_t
time_t
time_t是一个有符号的整数类型,表示的含义是从1970年1月1日到某一个时间点的秒数。若为32位系统,由int类型的范围可以推算出,time_t可以表示的时间范围是1901-12-13 20:45:52到2038-01-19 03:14:07。
struct ime_b
time_b结构体是一个精确到毫秒的结构体,其有四个成员,成员列表如下:123456struct timeb{ time_t time; unsigned short millitm; short timezone; //时区标志 short dstflag; //夏令时标志};
可以通过下列函数获取当前的timeb:1int ftime(struct timeb* tb);
struct timeval
timeval是一个精确到微妙的结构体。其中主要包含两个成员:1234struct timeval{ time_t tv_sec; suseconds tv_usec;};
此值通常通过gettimeofday获取12int gettimeofday(struct timeval* tv, struct timezone* tz); //timezone参数已废弃,一般设为NULL,
struct timespec
timespec是一个精确到纳秒的结构体。其主要包含两个成员1234struct timespec{ time_t tv_sec; //秒 long tv_nsec; //纳秒}
此结构体一般通过下列函数获取:12long clock_gettime(clockid_t which_clock, struct timespec* tp);
上述参数中which_clock用于标识那种时钟时间,可选值如下
- CLOCK_REALTIME : 系统当前时间,1970-1-1开始
- CLOCK_MONOTONIC : 系统的启动时间,不能被设置
- CLOCK_PROCESS_CPUTIME_ID : 进程运行时间
- CLOCK_THREAD_CPUITME_ID : 线程运行时间
- CLOCK_REALTIME_HR : CLOCK_REALTIME的高精度版本
- CLOCK_MONOTONIC_HR : CLOCK_MONOTONIC的高精度版本
struct tm
struct tm被称为一种分解时间,日期和时间被分解成多个独立字段。其形式如下:1234567891011struct tm { int tm_sec; //秒 (0-60) int tm_min; //分 (0-59) int tm_hour; //时 (0-23) int tm_mday; //日 (1-31) int tm_mon; //月 (0-11) int tm_year; //年 (1900-) int tm_wday; //一周中的周几(周日为0) int tm_yday; //一年中的第几天。(1月1号为0) int m_isdst; //DST大于0表示为夏令时时间。}
Unix时间相关函数
Unix时间相关的函数除了上面已经提到的函数还包括以下函数
- time(time_t timep)
- ctime
- gmtime
- localtime
- mktime
- asctime
- strftime
- strptime
time
函数原型
|
|
time函数返回当前时间的时间戳,此时间戳为从1970年1月1日到当前时间的时间戳,此值不受时区和夏令时(DST)。此函数的返回值为当前的时间戳,函数参数为time_t指针,当前时间除了返回值之外,还将此时间放入timep中。所以使用time函数时我们将timep设置为NULL即可。
ctime
函数原型
|
|
函数功能
ctime函数的功能为将time_t转化为打印字符串格式。把一个指向time_t的指针timep传入函数ctime,将返回一个长度为26字节的字符串,包含\0和换行符。ctime进行转换的时候,会考虑时区和夏令时,所以返回的时间字符串为当地时间。返回时间的格式如下:1Wed Jun 8 14:22:34 2011
特别注意返回的字符串是经由静态分配的,若多次调用此函数,之前获取的时间会受影响。SuSv3规定,调用ctime(),gmtime(),localtime()以及asctime()中的任意一个函数,都可能覆盖其他函数返回的结果。
静态分配的意思是这些函数返回的数据都是般存在同一个静态变量中,所以下一次的结果会覆盖上一次的数据。如果需要对之前的数据保存,此时需要将结果拷贝到自己分配的内存中。
### gmtime和localtime
函数原型
|
|
函数功能
gmttime和localtime的作用是将time_t值转换为分解时间struct tm类型。他们的主要区别是gmtime转换为对应于UTC的分解时间,而localtime考虑时区和夏令时。
mktime
函数原型
|
|
#### 函数功能
mktime的作用是将一个本地时区的分解时间转化为time_t类型。需要注意的是,mktime可能改变timeptr所指的内容。若分解时间不符合要求,mktime将其自动转换为有效时间。如秒为61,此时会将其变成1并讲分加1。
asctime
函数原型
|
|
函数功能
asc的功能是将分解时间转化为打印时间,特别注意的是asctime转化的过程中不考虑时区和夏令时,返回的数据也是静态分配的。
strftime
函数原型
|
|
函数功能
此函数的功能是将分解时间转换为打印时间,并可以指定打印时间的格式为format。不同于ctime和asctime,strftime结果不包含换行符。若返回的字符串超过了maxsize大小,函数返回0指示为转换错误。定义的格式中其格式化字符串可以参考预定义的格式。参考《Linux/Unix系统编程手册.上册》第158页。
Unix标准IO文件流及缓冲类型
Unix标准IO文件流
在文件IO相关函数的一节中,我们所有的I/O函数都是围绕着文件描述符来操作的,当打开一个文件的时候,即返回一个文件描述符,然后该文件描述符用于后续的文件操作。而对于标准IO库,对于文件的操作都是围绕这 文件流 file stream进行的。当我们使用标准IO库打开或创建一个文件的时候,我们已经使一个流和一个文件进行关联。
文件流
由于历史原因,C语言中原来表示流的数据结构是FILE,而不是叫做流。由于大多数的库函数使用到了FILE类型,有的时候在使用FILE指针的时候也叫其为流,这导致后来很多数据把FILE和流搞得十分混乱。实际上流就是标准IO库中程序与文件交互的一种方式。
标准IO函数fopen打开一个文件时返回一个指向FILE对象的指针,该对象通常是一个结构,它包含了标准IO库为管理该流所需要的所有信息,包括该文件的文件描述符,用于指向该流缓冲区的指针,缓冲区的长度,当前缓冲区中的字符数以及出错标志等等。
标准输入,标准输出以及标准错误
标准库中对于每一个进程都预定义了三个流,分别是stdin,stdout以及stderr,他们分别对应与Linux文件IO中的STDIN_FILENO,STDOUT_FILENO和STDERR_FILENO。它们的定义在stdio.h中
I/O文件流的缓冲类型
标准IO提供缓冲的目的是为了通过减少使用read和write调用的次数来提高IO读写的效率,它对每个IO流自动的进行缓冲处理,从而避免了用户程序在使用read和write需要考虑的这一点。
标准IO流提供了三种缓冲。分别是全缓冲(fully buffering),行缓冲(line Buffering)以及无缓冲(nonBuffering)。
全缓冲
在使用全缓冲的情况下,当数据填满整个缓冲区之后才进行实际的IO操作。对于驻留在磁盘上的文件的读写通常是使用全缓冲。通常如果不给文件流指定缓冲区的情况下,标准IO函数会首先调用malloc函数获取所需要的缓冲区。
行缓冲
在使用行缓冲的情况下,每当输入输出遇到换行或者缓冲区满了的情况下才会进行实际的IO操作,当涉及到终端输入输出的时候通常使用行缓冲。
对于行缓冲有两个限制。1.由于接收行缓冲的缓冲区的长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会进行IO操作。2.任何时候,只要通过IO库要求从一个不带缓冲的流或者一个行缓冲的流得到输入数据,那么就会冲洗所有缓冲输出流。
###不带缓冲
此时标准IO库不对字符进行缓冲存储。这就使得输入流要求IO立即进行,如标准错误流,若果出现错误,会立马输出。
flush一个流即刷新缓冲区有两个含义。
- 在IO库方面,flush意味着将缓冲区中的内容写到磁盘上,该缓冲区可能还没有满
- 在终端驱动方面表示丢弃已经存储在缓冲区中的内容。
##标准文件流与缓冲类型之间的关系
- 当标准输入输出指向的是交互式设备(如终端)的时候,它们是行缓冲的,若不是则是全缓冲的。
- 标准错误永远是无缓冲的。
与缓冲相关的函数
我们可以通过一下两个函数对将缓冲关闭或者改变缓冲的类型。其中这些函数应该在流被打开之后调用,而且也应该在对流进行一切操作之前调用。
|
|
使用setbuf函数打开或者关闭缓冲,当buf是一个有效缓冲区时,此时缓冲打开,若流指向的是终端设备,则此时该流是行缓冲的,否则该流是全缓冲的;当buf为NULL的时候,表示关闭该缓冲。
使用setvbuf可以精确的说明缓冲的类型,这里是使用mode来说明的,mode的值包括以下几个:
- _IOFBF 全缓冲
- _IOLBUF 行缓冲
- _IONBUF 无缓冲
如果指定一个不带缓冲的流,则忽略buf和size参数。如果指定缓冲,则buf和size分别指定一个缓冲区域和缓冲区域的长度。若此时buf为NULL,则标准IO库将自动制定一个适合长度的缓冲区。
上述函数与缓冲之间的关系
| 函数 | mode | buf | 缓冲区及长度 | 缓冲类型 |
|---|---|---|---|---|
| setbuf | 非空 | 长度为size的缓冲区buf | 全缓冲或行缓冲 | |
| setbuf | NULL | 无缓冲区 | 不带缓冲 | |
| setvbuf | _IOFBF | 非空 | 长度为size的缓冲区buf | 全缓冲 |
| setvbuf | _IOFBF | NULL | 合适长度的缓冲区buf | 全缓冲 |
| setvbuf | _IOLBF | 非空 | 长度为size的缓冲区buf | 行缓冲 |
| setvbuf | _IOLBF | NULL | 合适长度的缓冲区buf | 行缓冲 |
| setvbuf | _IONBF | 忽略 | 无缓冲区 | 不带缓冲 |
我们还可以通过fflush强制冲洗一个流,此函数使该流所有未写的数据都被传送到内核。作为一种特殊的情况,当流的NULL时,所有的流将被冲洗:12int fflush(FILE* fd);
Unix环境变量
概述
在Unix中,每个进程都有自己的一组环境变量,这些环境变量,要么是一组全局字符串,要么是子进程从父进程继承而来的,如果子进程不对其修改则与父进程的环境变量一模一样。
Unix内核并不查看这些字符串,它们的解释权完全取决于各个应用程序。例如shell是Unix中一个可执行程序,通常shell的启动文件中会对环境变量进行设置。所以当我们进入shell之后可以查看path等环境变量。在当前shell中启动的进程会继承其父进程shell的环境变量,也就可以查看path等环境变量,环境变量可以在登录的时候自动设置,也可以由用户自行设置。
环境变量相关变量
每个程序都会接收到一张环境表。与参数表一样,环境表也是一个字符指针数组。其中每个指针都包含一个以NULL结尾的字符串的地址。全局变量
environ指向了这个数组的地址。
代码如下:12345678910#include <stdio.h>#include <unistd.h>#include <stdlib.h>extern char **environ;if (environ!= NULL) { for (i = 0; environ[i] != NULL; i++) { printf("env: %s\n", environ[i]); }}
环境变量相关的函数
与环境变量相关的函数包括以下几种:取环境变量的值,添加环境变量、修改环境变量、以及删除环境变量.
|
|
putenv和setenv的区别
putenv可以使用程序中已经定义的且形如”name=value”的字符串作为参数。此时系统不再为该环境变量分配内存,环境变量将使用程序中定义变量的内存。
并将该字符串的地址保存在环境变量中。所以要使用putenv一定要用全局变量作为参数,否则程序退出栈内存被释放,再次访问环境变量将会出现未定义行为,
导致环境变量不可用。
putenv也可用字符串常量做参数,这个时候系统将为其分配内存。
但是setenv去设置环境变量系统将会先malloc出一块内存给环境变量使用,所以此时不需要担心环境不可用的情况。
环境变量在进程空间中的存储位置
环境变量和环境字符串通常放在进程存储空间的顶部,也就是栈内存之上。12345678910#include <stdio.h>#include <unistd.h>#include <stdlib.h>extern char **environ;int main() { int i; printf("the address of the environment: %p\n", environ); printf("the adress of first i: %p\n", &i);}
环境变量中进行增删改操作的实现机制
删除环境变量比较容易,当增加或者修改环境变量的时候由于环境表和环境字符串通常占用的是进程地址空间的顶部,所以它不能再向
高地址(向上)扩展,同时也不能在移动在它之下的各栈帧,所以也不能向下扩展。两者的组合使得该空间的长度不能再增加。
- 删除环境变量:删除环境变量时只需要先找到该指针,然后将所有后续指针都向环境表的首部顺序移一个位置。
- 修改环境变量:
- 若新的环境变量value长度小于或者等于原有的值,则直接将其复制到旧值。
- 否则,先调用malloc在堆上分配一块内存,然后将新字符串指向该空间,接着使环境变量表中针对name的指针指向新分区。
- 增加环境变量: 增加新环境变量比较复杂。必须首先通过调用malloc为新的name=value分配内存空间,然后将字符串复制到此空间中。
- 如果该name是第一次增加,则必须调用malloc为新的指针表分配内存空间,然后将原来的环境表复制到新的内存,并将指向新的name=value字符串
的指针存放在该指针表的表尾,然后将空指针放在其后面。最后使environ指向新的环境表。这样就导致原来位于栈顶之上的环境表移到了堆内存中。
但是大多数的环境指针仍然指向栈顶之上的name=value字符串。 - 如果不是第一次新增加一个name,可知之前已经将环境表迁移到堆内存中,所以只需要调用realloc,以分配比原空间多存放一个指针的空间。然后将指针指向name=value
字符串的指针,最后是一个NULL指针。
- 如果该name是第一次增加,则必须调用malloc为新的指针表分配内存空间,然后将原来的环境表复制到新的内存,并将指向新的name=value字符串
Unix文件IO相关函数
Unix中大多数文件的操作只需要用到五个函数open、read、write、lseek、和close。本章将详细讲解这些函数的用法以及参数详解。
文件描述符
对于内核而言,所有打开的文件都是通过文件描述符进行引用。文件描述符是一个非负整数。当打开或者创建一个文件的时候,内核向进程返回一个文件描述符。当对这个文件进行读写的时候,将这个参数传递给read或write。LINUX用于IO的数据结构一章中讲了STDIN_FILENO、STDOUT_FILENO以及STDERR_FILENO所对应的文件描述符。
为了保证系统资源的合理使用和安全性,Unix系统对于系统和用户能打开的文件描述符的格式都做了一定的限制。通过一下命令我们可以进行查看:
|
|
文件描述符与文件指针的关系
文件描述符:内核会为每一个运行中的进程在进程控制块(pcb)中维护一个打开文件的记录表,每个表项都有一个指针指向打开的文件,文件描述符就是记录表的索引。
文件指针:C语言使用文件指针而不是文件描述符作为文件IO的句柄,文件指针是指向进程的用户空间中的一个FILE结构的数据结构,FILE结构中包括一个IO缓冲区和一个文件描述符,而文件描述符是
文件描述符表的一个索引,从某种意义上可以将文件指针理解为文件句柄的句柄。
|
|
- 文件指针相比于文件描述符是高级的接口.
- 文件指针使用fread()和fwrite()函数进行操作,文件描述符使用write()和read()函数进行操作
- 文件指针具有缓冲区,是较高级别的IO,读写时具有缓冲,具有错误指示和EOF检测;文件描述符没有
- 文件指针具有移植性,文件描述符不能移植到除Unix之外的系统。
- fopen在stdio.h中,open在fcntl.h中
- fopen是标准C中定义的,而open是posix中定义的。
- fwrite/fread处理的速度快于read/write,但是在内存方面read/write性能较好。
函数open()和openat()
函数原型
|
|
返回值说明
若文件打开失败返回-1,打开失败原因可以通过errno或者strerror(errno)查看;
若成功将返回最小的未用的文件描述符的值。
参数说明
- path为要打开的文件的文件路径
- oflag为文件打开模式.
- …为可变参数,可以视情况添加
文件打开模式
文件打开模式标识当前进程对打开文件的操作权限。通常用一个或者多个权限的或来表示。权限列表如下:
| flag | 含义 |
|---|---|
| O_RDONLY | 只读权限 |
| O_WRONLY | 只写权限 |
| O_RDWR | 读写权限 |
| O_EXEC | 可执行权限 |
| O_SEARCH | 搜索权限(针对目录) |
| O_APPEND | 每次写都追加到文件的末端 |
| O_CLOEXEC | 把close_on_exec设置为文件描述符标识 |
| O_CREATE | 若文件不存在,则创建它。使用此选项的时候,需要使用第三个参数指定该新文件的访问权限位 |
| O_DIRECTORY | 如果path不是目录则出错 |
| O_EXCL | 若同时执行了O_CREATE,若文件存在则出错,可以用此选项测试文件是否存在 |
| O_NOCTTY | 如果PATH引用的是终端设备,则不将该终端设备作为该进程的控制终端 |
| O_NOFOLLOW | 若PATH引用的是符号链接,则出错 |
| O_NONBLOCK | 如果path引用的是FIFO,一个块特殊文件或者一个字符特殊文件,则将文本打开操作和后续的IO设置为非阻塞模式 |
| O_SYNC | 使每次write等待物理IO完成,包括该write属性引起的文件属性更新需要的IO |
| O_TRUNC | 如果文件存在,且打开模式为只写或者读写,则将文件内容截断为0 |
| O_TTY_INIT | 如果打开一个还未打开的终端设备,设置非标准termios参数值,使其符合Single Unix Specification |
| O_DSYNC | 每次write要等待物理IO操作完成,但是如果该写操作并不影响读取刚写入的数据,则不需要等待文件属性被更新 |
| O_RSYNC | 使每一个以文件描述符作为参数进行的read操作等待,直至所有对文件同一部分挂起的写操作完成 |
文件访问权限mode_t
mode的值表示了对文件的访问权限。这个访问权限与使用shell命令chmod去修改文件的权限的含义相同,文件的权限包括三大类,分别是当前文件对于文件所有者(u),文件所有者所在的组(g)以及其他
用户(o)而言,对这三种角色又分别具有读写可执行的权限。所以这个参数只有在创建文件的时候才用到,用来指定当前创建的文件所对应的权限。
| mode | 含义 |
|---|---|
| S_IRUSR | 用户读 |
| S_IWUSR | 用户写 |
| S_IXUSR | 用户可执行 |
| S_IRGRP | 组读 |
| S_IWGRP | 组写 |
| S_IXGRP | 组可执行 |
| S_IROTH | 其他读 |
| S_IWOTH | 其他写 |
| S_IXOTH | 其他可执行 |
需要注意的是,目录的可执行权限以及读权限与文件的相应权限完全不同。目录的可执行权限表示搜索位,即可搜索权限,若目录不具有可执行权限则不能cd进入文件;
目录的读权限是可以查看目录中文件内容的权限,若文件夹不具有读权限,则ls不能显示目录内的内容。
open与openat的区别
open和openat的区别主要在fd上
- path参数指定的是绝对路径名,在这种情况下,open与openat相同,fd忽略.
- path参数是相对路径名,fd参数指出了相对路径名在文件系统中的开始地址。fd参数通过打开相对路径名所在的文件目录获取。即此时fd为打开相对路径所获取的文件描述符。
- path参数为相对路径,fd参数为AT_FDCWD,此时相对路径为当前目录,作用于open相同。
函数create()
函数原型
|
|
返回值说明
若文件创建失败返回-1;
若创建成功返回当前创建文件的文件描述符。
参数说明
参数与open中对应的参数含义相同
函数功能说明
create(path, mode)函数功能为创建新文件,与open(path, O_CREATE|O_TRUNC|O_WRONLY)功能相同。
函数close()
函数原型
|
|
返回值说明
文件关闭成功返回0,关闭失败返回-1.
函数功能介绍
该函数的作用是关闭指定文件描述符的文件,关闭文件时还会释放该进程加在该文件上的所有的记录锁。当一个进程终止时,内核自动关闭它所有打开的文件。很多程序都是利用这一功能而不是close
函数关闭打开的文件。但是对于长期运行的函数,最好还是使用close关闭打开的文件。
lseek()函数
每个打开的文件在文件表项中存在着对应的当前文件的偏移量(current file offset),通常为非负整数。文件的读写操作都是从当前偏移量开始,并在操作后将偏移量增加相应的字节数。当打开文件
模式为O_APPEND时,该文件的offset是文件末尾,除此之外,其他情况都被初始化为0.
函数原型
|
|
返回值说明
成功则返回新的文件的偏移量;
失败则返回-1.
函数功能
使用lseek()函数显式的为一个打开的文件设置偏移量。lseek仅将文件的偏移量记录在内核中,并不引起IO开销。
参数说明
参数offset的解释与whence相关。
- 若whence为SEEK_SET,则将该文件的偏移量设置为距离当前文件开始处offset字节。
- 若whence为SEEK_CUR,则将该文件的偏移量设置为距离当前偏移量加offset个字节,此时offset可正可负。
- 若whence为SEEK_END,则将该文件的偏移量设置为当前文件长度加offser个字节,此时offset可正可负。
|
|
注意一般情况下文件的偏移量不能为负值,但是一些特殊的文件允许偏移量为负值,如在FreeBSD上运行的设备/dev/kmem支持负的偏移量。
因为偏移量可能为负值,所以在比较偏移量的时候不能直接判断其是否小于0,而是要判断其是否等于-1.文件的偏移量允许大于文件的长度,这时会在文件中出现一些空洞,但是是被允许的。文件中的空洞并不在文件中占磁盘块(block)。
read()函数
函数原型
|
|
返回值说明
若读取成功,读到文件末尾返回0,未读到文件末尾返回当前读的字节数。
若读取失败,返回-1。
参数说明
fd为要读取文件的文件描述符。buf为读取文件数据缓冲区,nbytes为期待读取的字节数,通常为sizeof(buf)。
注意read函数默认读入多行,遇到换行不会停止读入,直到读到文件末尾,下一次读取返回值为0.
write()函数
函数原型
|
|
返回值说明
若写入成功则返回写入的字节数;失败返回-1.
参数说明
buf为写入内容的缓冲区,ntyes为期待写入的字节数,通常为sizeof(buf)。一般情况下返回值与ntypes相等,否则写入失败。
当指定O_APPEND选项,内容将从文件末尾写入,否则从文件开始写入。一般情况下将缓冲区的长度设置为磁盘块的大小可以最大程度的提升程序读写的性能。
Unix错误处理
当Unix系统函数出错的时候,通常会返回一个负值,同时整型变量errno通常被设置为具有特定信息的值。例如当使用open打开文件的时候,若当前文件不存在,此时open的返回值为-1,errno被设置为2(ENOENT)。
系统函数出错的返回值不一定为负数,是根据具体函数具体定义的,如当系统函数返回一个指针时,若出错,将会返回NULL。
Linux系统中errno.h中定义了一系列的错误宏,他们之处了不同错误对应的错误ID,为整型变量,可被赋值。
关于errno需要注意的两点:
- 如果没出错,errno将不会被进程设置,所以一般当利用函数返回值确认已经出错的时候,再去查看相应的errno
- 任何函数不会讲errno的值设置为0,而且在errno.h中定义的所有宏定义都不为0
Unix错误处理的两个相关函数
strerror函数
函数原型
|
|
函数功能
此函数的功能为将errno转化为其对应的具体错误信息。
示例代码
|
|
perror函数
函数原型
|
|
函数功能
perror基于当前errno的值,在标准错误流上输出一个出错信息。输出内容首先输出msg所指的字符串,然后一个冒号,空格,接着是errno对应的错误字符串,最后是一个换行符。
示例代码
|
|
一些特殊的错误
EAGAIN,EWOULDBLOCK和EINTR
在Linux环境下开发经常会碰到很多错误(设置errno),其中EAGAIN是其中比较常见的一个错误(比如用在非阻塞操作中)。
从字面上来看,是提示再试一次。这个错误经常出现在当应用程序进行一些非阻塞(non-blocking)操作(对文件或socket)的时候。
例如,以 O_NONBLOCK的标志打开文件/socket/FIFO,如果你连续做read操作而没有数据可读。此时程序不会阻塞起来等待数据准备就绪返 回,
read函数会返回一个错误EAGAIN,提示你的应用程序现在没有数据可读请稍后再试。
又例如,当一个系统调用(比如fork)因为没有足够的资源(比如虚拟内存)而执行失败,返回EAGAIN提示其再调用一次(也许下次就能成功)。
EAGAIN:Linux - 非阻塞socket编程处理EAGAIN错误
在linux进行非阻塞的socket接收数据时经常出现Resource temporarily unavailable,errno代码为11(EAGAIN),这是什么意思?
这表明你在非阻塞模式下调用了阻塞操作,在该操作没有完成就返回这个错误,这个错误不会破坏socket的同步,不用管它,下次循环接着recv就可以。
对非阻塞socket而言,EAGAIN不是一种错误。在VxWorks和Windows上,EAGAIN的名字叫做EWOULDBLOCK。
另外,如果出现EINTR即errno为4,错误描述Interrupted system call,操作也应该继续。
最后,如果recv的返回值为0,那表明连接已经断开,我们的接收操作也应该结束。
错误恢复
我们可以将errno.h中定义的错误分为两种,分别是致命的和非致命的,对于致命性错误,无法执行恢复操作。对于非致命性错误,大多数来说是暂时的。
对于非致命性错误,最常用的做法就是延迟一段时间,然后重试。例如当错误表示网络不可用,这时我们将可以通过延迟一段时间,进行重新连接。
errno宏定义及相应解释
|
|
Unix基础知识
Unix体系结构
从严格意义上讲,可以将操作系统定义为一种软件,它相当于一种控制计算机硬件资源,为程序提供运行环境的软件。我们通常将这种软件叫做内核,因为它相对比较小,并且位于环境的核心。Unix体系结构如下图: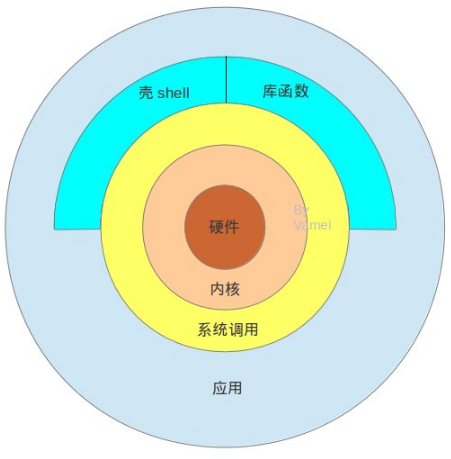
内核的接口被称为系统调用(system Call),公共库函数建立在系统调用接口之上,应用程序既可以使用公共函数库,也可以使用系统调用。shell是一个特殊的应用程序,为运行其他应用程序提供了接口。
Unix文件和目录
文件系统
Unix文件系统是文件和目录的一种层次结构,所有文件的起点都是根目录(root),名称为”/“.
目录是一个包含目录项的文件。逻辑上,可以认为每个目录项都包含一个文件,同时还说明该文件属性的信息。文件属性包括文件类型(普通文件还是目录)、文件权限、;链接到改文件的进程数、文件所有者、文件所有者所在的组 文件大小以及文件最后修改的时间等。stat和fstat函数返回一个文件属性的信息结构。
|
|
使用C语言实现ls功能
涉及到的相关函数:
- 文件夹操作函数opendir,readdir,closedir
- opendir返回指向dir结构的指针,将该指针传递给readdir,无需关心dir结构中存在什么数据,直接读取即可。
|
|
输入和输出
文件描述符
文件描述符是一个很小的非负整数,内核用文件描述符来标识一个特定进程正在访问的文件。当内核打开或创建文件时,他都会返回一个文件描述符。在读写文件时,都可以使用这个描述符(根据打开时的模式赋予权限).
标准输入、标准输出和标准错误流
按照惯例,每当运行一个新程序的时候,所有的shell都会为改程序默认打开三个文件描述符,即标准输入,标准输出和标注错误。如果不做特殊处理,这三个描述符都连接到终端,也可以将其重定向到文件。如ls > test.data