Linux用于I/O的数据结构及fcntl函数详解
Linux内核用于IO的数据结构
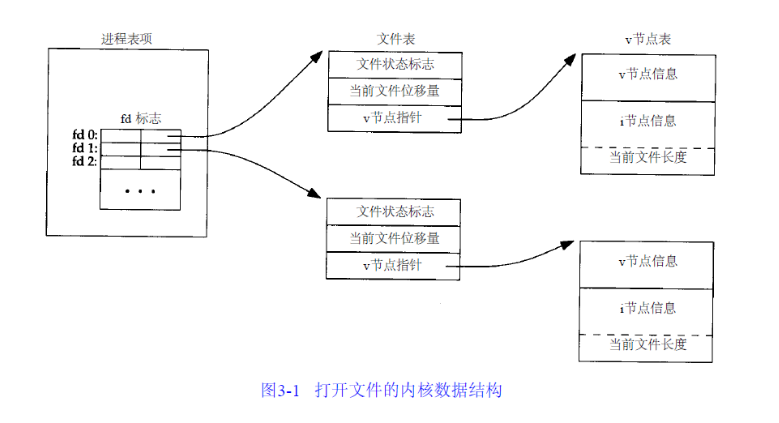
内核使用三种数据结构表示打开的文件,它们之间的关系决定了在文件共享方面一个进程对另一个进程可能产生的影响.
- 进程表项 每个进程在记录表中都有一个记录项,记录项中包含一张打开的文件描述符表,可将其视为一个矢量,每个描述符占用一项。与每个文件描述符相关联的是:
- 文件描述符标志(close_on_exec,close_on_exec是一个进程所有文件描述符的标记位图,每个比特位代表一个打开的文件描述符,用于确定在系统调用execve()时需要关闭的文件句柄)。
- 指向一个文件表项的指针
- 文件表项 内核为所有打开文件维护一张文件表(不同进程打开相同文件将有两条记录),每个文件表项中包括:
- 文件状态标志(read,write,append,async,nonblock等)
- 当前文件偏移量
- 指向该文件v(i)节点表项的指针
- 节点表项。每个打开的文件都有一个v-node结构,v-node中包含了文件类型和对此文件进行各种操作函数的指针。对于大多数文件,V-node中还包含了文件inode节点信息,这些信息是打开文件时从磁盘上读入内存的,所以文件所有信息都是随时可用的。
- v节点的信息
- 当前文件的长度
- i节点的信息
close_on_exec是一个进程所有文件描述符(文件句柄)的位图标志,每个bit代表一个打开的文件描述符,用于
确定在系统调用execve()时是否需要关闭文件句柄。当一个进程fork出一个子进程时,通常会在子进程中调用execve()函数
加载执行另一个新程序。此时子进程将完全被新程序替换掉,并在子进程中执行新程序。若一个文件描述符在close_on_exec中对应的
bit被设置,那么在执行execve()时该文件描述符将被关闭,否则该文件描述符将始终处于打开状态。
当打开一个文件的时候,默认情况下文件句柄在子进程中也处于打开状态。
注意文件描述符和文件描述符标志的区别,文件描述符是文件进程打开文件时的文件句柄,文件描述符标志为close_on_exec。
下图显示了一个进程打开两个不同文件时三张表对应的关系:
如果两个独立的进程同时打开同一个文件,三张表之间的对应关系如下:
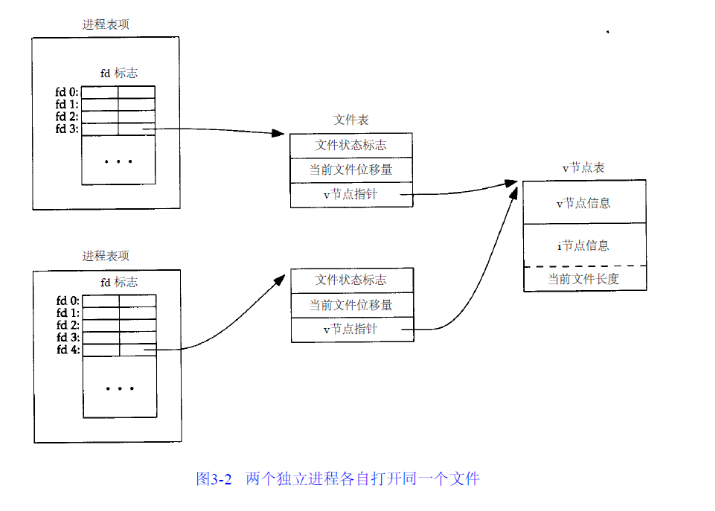
从上面可以看出,不同进程打开相同的文件时每个进程将获得各自的文件表项,这是因为不同的进程都有各自的文件偏移量。
当我们对文件进行操作的时候,上面三种表项之间的变化关系如下:
- 当对文件进行写操作时(write),在文件表项中的文件偏移量将增加写入的字节数。如果此时文件偏移量超过了文件长度,更新文件长度为当前的文件偏移量
- 当用O_APPEND标志打开一个文件,则相应的标志也被设置到文件表项的文件标志状态中。每次对这种具有追加标志的文件进行写操作时,首先将当前文件偏移量设置为文件文件长度,这就使得每次增加的内容都会写到文件末尾。
- 若使用lseek定位到文件末尾,则文件表项中偏移量被设置为文件长度
- lseek函数只修改文件表项中的偏移量,不进行任何IO操作。
注意问题:
- 可能有多个文件描述符指向同一个文件表项,如在fork的时候就有可能发生
- 注意文件描述符和文件状态标志在作用范围方面的区别。前者只用于一个进程的描述符,而后者则应用于指向该给定文件表项的任何进程中的所有描述符。
函数fcntl功能及用法
函数原型:
|
|
函数功能:
fcntl的作用是改变已经打开的文件属性。
参数说明:
- fd 为file descriptor,即文件打开之后的文件描述符
- cmd为命令,即需要对fd操作的命令,一般为几个宏定义中的其中一个
- args 参数,此参数为执行cmd命令所需要的参数
cmd参数命令及功能:
fcntl的功能可以分为5种:
- 复制一个已有的文件描述符
- cmd = F_DUPFD,此功能*返回一个文件描述符,新的描述符的值为大于或等于args的可用的(尚未打开)文件描述符的最小值,新描述符与fd共用一个文件表项。但是新的文件描述符有它自己的一套文件描述符标志.
- cmd = F_DUPFD_CLOEXEC.与上述功能一致,唯一不同的是使用此命令会设置CLOSE_ON_EXEC,
即当执行execve的时候,文件描述符将被关闭。
- 获取或设置文件描述符标志
- cmd = F_GETFD 返回与fd关联的close_on_exec标志,第三个参数被忽略。
- cnd = F_SETFD 将文件描述符标志close_on_exec设置为第三个参数。
- 获取或设置文件状态标志
- cmd = F_GETFL 获取fd对应的文件的状态标志(存储于文件表项)
- cmd = F_SETFL 设置fd对应文件的状态标志
- 获取或设置异步IO所有权
- cmd = F_GETOWN 获取当前接受SIGIO和SIGURG信号的进程IO或者进程组ID。
- cmd = F_SETOWN 设置接受SIGIO和SIGURG信号的进程ID或进程组ID。返回值为正则为进程,返回值为负数即为进程组。
- 获取或记录锁(cmd=F_GETLK、F_SETLK、F_SETLKW),此处不详解
文件状态标志说明:
文件状态标志存储与文件表项中,它用于说明进程对当前文件的可操作权限。文件的
操作权限说明如下图表所示,权限设置可使用|或者&进行设置.
| 文件状态标志 | 功能说明 |
|---|---|
| O_RDONLY | 只读权限 |
| O_WRONLY | 只写权限 |
| O_RDWR | 读写权限 |
| O_EXEC | 可执行权限 |
| O_SEARCH | 只搜索打开权限 |
| O_APPEND | 追加写 |
| O_NONBLOCK | 非阻塞模式 |
| O_SYNC | 等待写完成(数据和属性) |
| O_DSYNC | 等待写完成(仅数据) |
| O_RSYNC | 同步读写 |
| O_FSYNC | 等待写完成 |
| O_ASYNC | 异步IO |
注意O_RDONLY、O_WRONLY、O_RDWR、O_EXEC、O_SEARCH这个五个标志并不各占
一位,一个文件的访问方式只能取这五个里面的一个。因此检查当前文件的是这
五个标志中的哪一个需要使用屏蔽字O_ACCMODE取得当问方式位,在于这五个标志
进行对比。
代码示例说明
STDIN_FILENO,STDOUT_FILENO以及STDERR_FILENO
STDIN_FILENO等是系统API接口库中
对应的主要函数有open,read,write和close等。
STDIN_FILENO的含义是标准输入(键盘)的文件描述符,STDOUT_FILENO是标准输出流的文件描述符,STDERR_FILENO
是标准错误流的文件描述符。
STDIN_FILENO与stdin的区别
- 数据类型不同 stdin的数据类型为FILE*,STDIN_NO的数据类型为int
- 可用的函数不同 stdin主要用的函数有fread,fwrite,fclose,STDIN_FILENO可用的函数为write,read和close
- stdin属于标准IO,高级的输入输出函数,在stdio.h中定义;STDIN_FILENO是文件描述符,一般定义为0,1,2,属于没有buffer的IO,直接调用系统调用,定义在unistd.h中
- 层次不同,stdin属于标注库处理的输入流,其声明为FILE*型,对应的函数前面都有f开头;而STDIN_FILENO属于系统API接口,对用的函数是一些系统级的调用