Unix网络编程之基础函数(一)
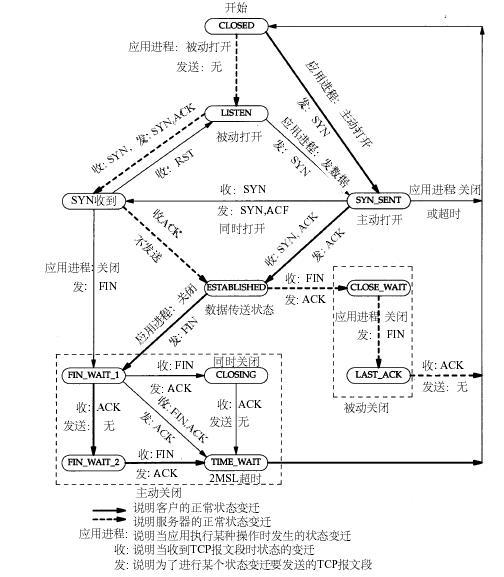
TCP客户端与服务器之间交互过程在程序实现上的体现如下图所示,注意思考这个过程中TCP状态的变化(参考TCP状态转换图):
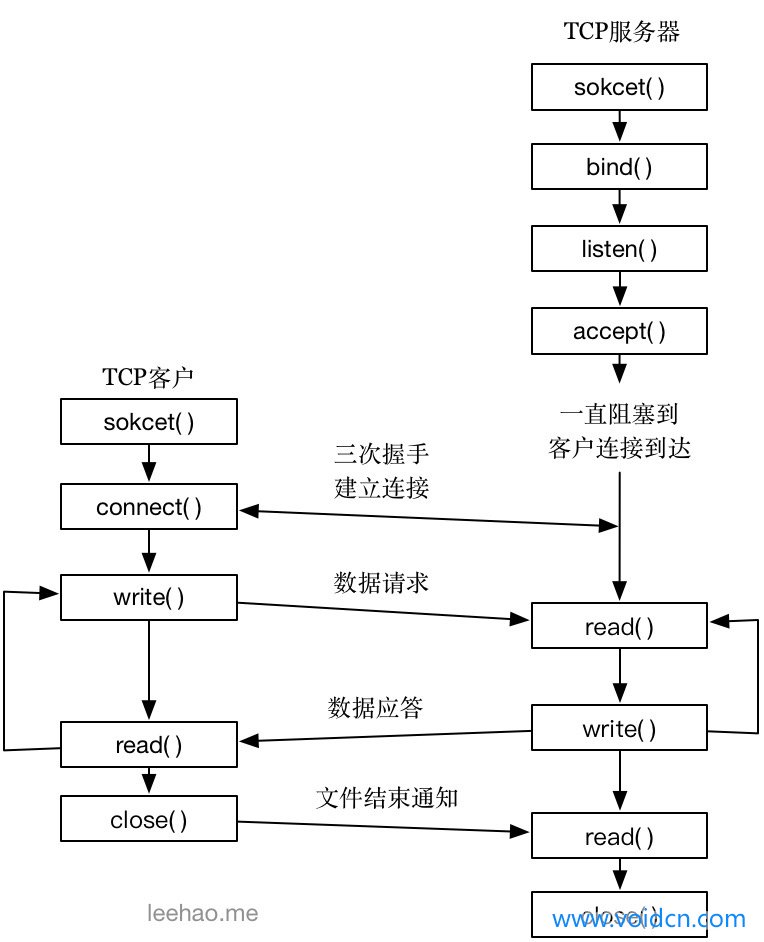
服务器首先调用socket函数创建socket,通过bind函数将socket与主机地址及端口绑定,然后调用listen函数对主机端口进行监听,然后调用accept函数接收客户端发来的请求,若没有客户端请求,服务端将阻塞在此。客户端建立socket,然后调用connect函数与服务器三次握手建立连接,发送请求给服务器,服务器接收到请求之后对其进行处理并将处理结果返回给客户端,这个过程一直持续下去,一直到客户端与服务器断开连接,服务器接下来将关闭连接或继续等待下一个客户端的连接。
socket函数
为了执行网络IO,无论是客户端还是服务器,一个进程首先要做的事情就是调用socket函数创建一个socket,并指定socket的协议族,类型以及协议。
函数原型
|
|
参数说明
- family : 协议族,对应于sockaddr_in中的sin_family,IPv4协议时值为AF_INET.
- type : 套接字类型,套接字类型有多种,TCP一般使用SOCK_STREAM,UDP使用SOCK_DGRAM
- SOCK_STREAM : 字节流套接字,是一种有序可靠双向的面向连接字节流的套接字
- SOCK_DGRAM : 数据报套接字,是一种长度固定,无连接的不可靠的套接字。
- SOCK_SEQPACKET : 有序分组套接字,是一种长度固定,有序,可靠的面向连接的有序分组套接字。
- SOCK_RAW : 原始套接字
- protocal : 链接层传输协议,包括TCP,UDP,SCTP传输协议
- IPPROTO_TCP : TCP传输协议
- IPPROTO_UDP : UDP传输协议
- IPPROTO_SCTP : SCTP传输协议
一般情况下,我们在使用socket函数的时候,可以只指定前两个参数,将第三个参数设为0,这个时候socket会将protocol设置为默认值,如当family=AF_INET,type=SOCK_STREAM时,这个时候默认的协议为IPv4 TCP协议。但是,注意有些组合是不可用的,组合如下:
| AF_TNET | AF_INET6 | AF_LOCAL | AF_ROUTE | AF_KEY | |
|---|---|---|---|---|---|
| SOCK_STREAM | TCP/SCTP | TCP/SCTP | 是 | ||
| SOCK_DGRAM | UDP | UDP | 是 | ||
| SOCK_SEQPACKET | SCTP | SCTP | 是 | ||
| SOCK_RAW | IPv4 | IPv6 | 是 | 是 |
返回值说明
socket函数与open函数类似,若成功,返回一个较小的非负整数,称为套接字描述符,若失败返回-1;
connect函数
TCP客户端通过connect函数来与服务器建立连接,注意客户在调用connect函数之前不必调用bind函数将sockfd与本机的IP端口绑定,因为如果需要的话,内核会确定源IP地址,并选择一个可用的临时端口作为端口号。
客户端调用connect函数的时候会激发三次握手连接建立。而且只在连接建立成功或失败时返回,否则会一直阻塞在connect函数处。
connect函数出错的情况包括以下几种:
- 若TCP在调用connect之后没有接收到syn分节,则返回ETIMEOUT错误。这种情况通常发生在目的主机不存在情况下。这时客户端会隔一段时间发送一次请求,若等待时间超过一定时间(这个过程客户端被阻塞),返回ETIMEOUT错误。
- 若T客户端收到RST分节(复位),则返回ECONNREFUSED错误,这种情况发生在目的主机存在,但是主机上没有进程监听指定端口。
- 若客户端发送的分节在某个路由器上返回destination unreachable,此时返回EHOSTUNREACH,这种情况发生在目的主机和端口存在,但是中间路由出现问题。
从TCP状态图可以看出,connect函数可以使得socket状态从closed转移到SYN_SENT状态,若成功,转换到ESTABLISHED状态。若套接字失败不可用,必须关闭。然后重新调用socket函数。
函数原型
|
|
参数说明
- sockfd : 此参数为调用sock函数的返回值,即套接字描述符
- servaddr : 指向服务器套接字地址结构的指针,套接字地址结构中必须含有Ip地址以及端口。
- addrlen : 上述套接字的长度。
返回值说明
连接失败,返回-1,并将错误码写入errno中;
若连接成功,则返回0.
bind函数
在建立socket之后,我们通常会将socket与一个套接字绑定,即将一个协议地址赋予给socket,bind函数的作用就是将socket与socket地址绑定。socket协议地址是32位的IPv4地址或128位的IPv6和16位的TCP或UDP端口的组合。
一般情况下,客户端一般不调用bind函数进行绑定socket地址(可调用),当其调用connect函数的时候,内核会获取主机的IP作为源IP,并选择一个可用的端口作为源端口,当然,客户端可以调用bind为socket指定源端口和IP;服务端一般要调用bind端口,为socket指定监听的端口和IP,因为一般情况下服务器是对外提供服务的,如http的80端口,https的443端口等等。
注意:socket绑定的端口必须是进程所在主机上的网络接口之一,不能是其他主机的IP,否则会出现“Cannot assign requested address”,也不能绑定已经在使用的端口。
函数原型
|
|
bind函数可以只绑定IP,只绑定端口,也可以两者都绑定,也可以两者都不绑定,具体的制定规则如下:
| IP地址 | 端口 | 说明 |
|---|---|---|
| 统配地址(INAAR_ANY) | 0 | 内核选择IP地址和端口 |
| 统配地址(INADDR_ANY) | 非0 | 内核选择IP地址,进程指定地址 |
| 本地IP地址 | 0 | 进程指定IP,内核选择端口 |
| 本地IP地址 | 0 | 进程指定IP和端口 |
一般情况下,INADDR_ANY的值为0,将其转化为s_addr的时候使用htonl函数(将主机字节序转化为网络字节序),若是IPv6则不能使用htonl,因为IPv6的地址是一个128位的地址。需要使用另一种方式,具体参考《Unix网络编程卷一第三版》83页。
若设置为内核选定端口,则必须调用getsockname函数获取系统选定的端口。
从bind函数返回的一个常见的错误是:EADDRINUSE : address already in use;
listen函数
函数原型
|
|
listen函数仅由TCP服务器调用,一般在调用socket和bind函数之后调用 .当进程调用socket函数创建套接字之后,这个套接字被默认假设为主动套接字,(主动套接字的意思是将会调用connect去和TCP服务器建立连接)。listen函数主要有以下两个作用:
- 将一个未连接的套接字转化为主动套接字,指示内核应该接收指向该套接字的连接请求。调用listen成功之后TCP从CLOSED状态转变为LISTEN状态。
- 指定内核应该为相应套接字排队的最大连接数。即backlog指定,下面两个队列的和不能超过backlog.若查过backlog还有连接请求,服务器将直接发送RST复位拒绝连接。一般不要吧backlog值设为0,因为不同系统实现对0的解释不同;一般讲backlog的值设为5,因为这是4.2BSD支持的最大值。
内核为任何一个给定的监听套接字维护两个队列:
- 未完成连接队列 :当服务器收到客户端发来的请求之后,数据还没有处理完,此时会进入SYN_RECV状态,这个时候将进入未完成连接队列,也叫SYN队列
- 已完成连接队列:服务器与客户端之间建立连接之后,进入ESTABLISHED状态,此时进入已完成连接队列,也叫accept队列。
accept函数
accept函数的作用是从已经完成连接的队列头返回下一个已经完成的连接,如果已完成的连接为空,则进程进入睡眠状态(阻塞)。
函数原型
|
|
参数说明
- servsockfd : 监听的套接字描述符
- cliaddr : 客户端的sockaddr,如果对客户端的来源不感兴趣,可以将其设置为NULL;
- addr_len : aliaddr的字节数。即客户端sockaddr的地址长度。
返回值说明
若出错返回-1;如果accept成功,返回一个新的socket描述符。其代表与所返回的客户端之间的TCP连接,它是一个连接套接字,之后服务端接收和发送数据都将使用这个描述符进行操作.
Invalid argument常见原因
在accept的时候,我们常会遇到Invalid argument的错误,出现这个错误的原因有很多,主要是在accept之前的准备工作出了问题。
- socket创建不成功,在socket函数后检查一下errno值
- 绑定socket地址不成功,检查一下返回值,同时检查一下errno
- 没有listen,或者listen出问题。
以上三步有一步出问题或者漏掉一步都有可能出现Invalid argument错误。
close函数
我们知道,关闭文件描述符我可使用close函数,同样的close函数也能用来关闭socket文件描述符。
通常情况下,close一个TCP套接字只是将该socket描述符标记为不可用,这个时候其将不能作为read和write的第一个参数进行数据的发送和接收,然而TCP尝试发送已经排队等待的所有需要发送到对端的数据,发送完毕之后将执行正常的TCP连接终止流程关闭TCP连接.