rapidjson创建型
|
|

|
|
我们常用ioctlsocket的FIONBIO模式对socket进行设置是否启用异步。1int ioctlsocket(int sockfd, long cmd, unsigned long* args);
ioctlsocket函数的作用是获取与套接字sockfd相关的操作参数,可用于任何状态的任一套接字,与具体的协议无关.
TCP客户端与服务器之间交互过程在程序实现上的体现如下图所示,注意思考这个过程中TCP状态的变化(参考TCP状态转换图):
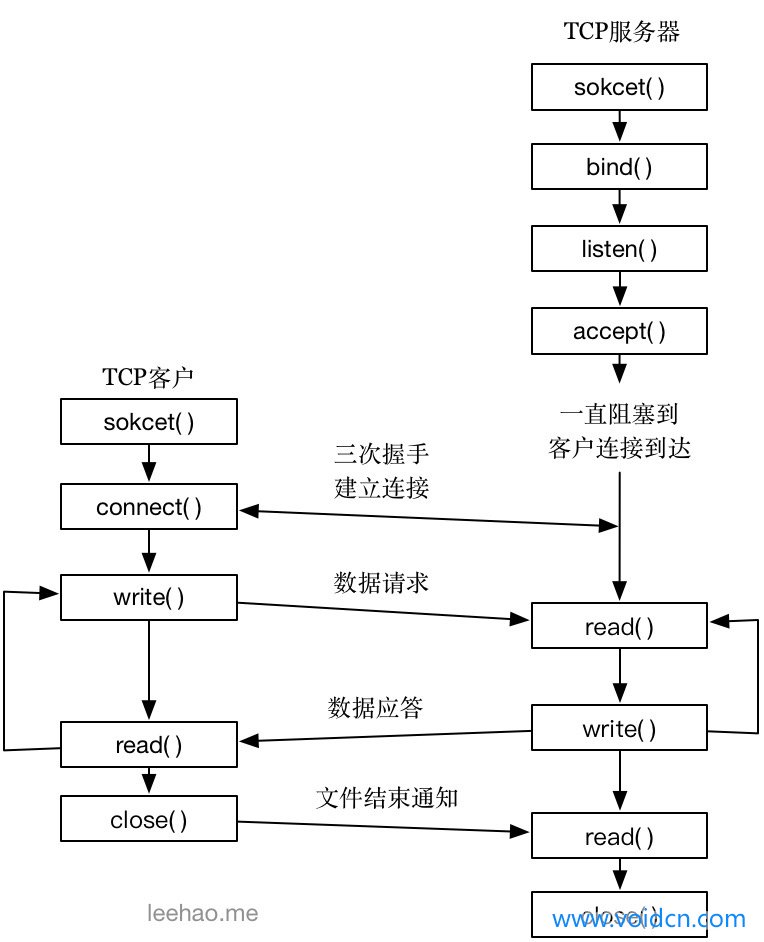
服务器首先调用socket函数创建socket,通过bind函数将socket与主机地址及端口绑定,然后调用listen函数对主机端口进行监听,然后调用accept函数接收客户端发来的请求,若没有客户端请求,服务端将阻塞在此。客户端建立socket,然后调用connect函数与服务器三次握手建立连接,发送请求给服务器,服务器接收到请求之后对其进行处理并将处理结果返回给客户端,这个过程一直持续下去,一直到客户端与服务器断开连接,服务器接下来将关闭连接或继续等待下一个客户端的连接。
为了执行网络IO,无论是客户端还是服务器,一个进程首先要做的事情就是调用socket函数创建一个socket,并指定socket的协议族,类型以及协议。
|
|
一般情况下,我们在使用socket函数的时候,可以只指定前两个参数,将第三个参数设为0,这个时候socket会将protocol设置为默认值,如当family=AF_INET,type=SOCK_STREAM时,这个时候默认的协议为IPv4 TCP协议。但是,注意有些组合是不可用的,组合如下:
| AF_TNET | AF_INET6 | AF_LOCAL | AF_ROUTE | AF_KEY | |
|---|---|---|---|---|---|
| SOCK_STREAM | TCP/SCTP | TCP/SCTP | 是 | ||
| SOCK_DGRAM | UDP | UDP | 是 | ||
| SOCK_SEQPACKET | SCTP | SCTP | 是 | ||
| SOCK_RAW | IPv4 | IPv6 | 是 | 是 |
socket函数与open函数类似,若成功,返回一个较小的非负整数,称为套接字描述符,若失败返回-1;
TCP客户端通过connect函数来与服务器建立连接,注意客户在调用connect函数之前不必调用bind函数将sockfd与本机的IP端口绑定,因为如果需要的话,内核会确定源IP地址,并选择一个可用的临时端口作为端口号。
客户端调用connect函数的时候会激发三次握手连接建立。而且只在连接建立成功或失败时返回,否则会一直阻塞在connect函数处。
connect函数出错的情况包括以下几种:
从TCP状态图可以看出,connect函数可以使得socket状态从closed转移到SYN_SENT状态,若成功,转换到ESTABLISHED状态。若套接字失败不可用,必须关闭。然后重新调用socket函数。
|
|
连接失败,返回-1,并将错误码写入errno中;
若连接成功,则返回0.
在建立socket之后,我们通常会将socket与一个套接字绑定,即将一个协议地址赋予给socket,bind函数的作用就是将socket与socket地址绑定。socket协议地址是32位的IPv4地址或128位的IPv6和16位的TCP或UDP端口的组合。
一般情况下,客户端一般不调用bind函数进行绑定socket地址(可调用),当其调用connect函数的时候,内核会获取主机的IP作为源IP,并选择一个可用的端口作为源端口,当然,客户端可以调用bind为socket指定源端口和IP;服务端一般要调用bind端口,为socket指定监听的端口和IP,因为一般情况下服务器是对外提供服务的,如http的80端口,https的443端口等等。
注意:socket绑定的端口必须是进程所在主机上的网络接口之一,不能是其他主机的IP,否则会出现“Cannot assign requested address”,也不能绑定已经在使用的端口。
|
|
bind函数可以只绑定IP,只绑定端口,也可以两者都绑定,也可以两者都不绑定,具体的制定规则如下:
| IP地址 | 端口 | 说明 |
|---|---|---|
| 统配地址(INAAR_ANY) | 0 | 内核选择IP地址和端口 |
| 统配地址(INADDR_ANY) | 非0 | 内核选择IP地址,进程指定地址 |
| 本地IP地址 | 0 | 进程指定IP,内核选择端口 |
| 本地IP地址 | 0 | 进程指定IP和端口 |
一般情况下,INADDR_ANY的值为0,将其转化为s_addr的时候使用htonl函数(将主机字节序转化为网络字节序),若是IPv6则不能使用htonl,因为IPv6的地址是一个128位的地址。需要使用另一种方式,具体参考《Unix网络编程卷一第三版》83页。
若设置为内核选定端口,则必须调用getsockname函数获取系统选定的端口。
从bind函数返回的一个常见的错误是:EADDRINUSE : address already in use;
|
|
listen函数仅由TCP服务器调用,一般在调用socket和bind函数之后调用 .当进程调用socket函数创建套接字之后,这个套接字被默认假设为主动套接字,(主动套接字的意思是将会调用connect去和TCP服务器建立连接)。listen函数主要有以下两个作用:
内核为任何一个给定的监听套接字维护两个队列:
- 未完成连接队列 :当服务器收到客户端发来的请求之后,数据还没有处理完,此时会进入SYN_RECV状态,这个时候将进入未完成连接队列,也叫SYN队列
- 已完成连接队列:服务器与客户端之间建立连接之后,进入ESTABLISHED状态,此时进入已完成连接队列,也叫accept队列。
accept函数的作用是从已经完成连接的队列头返回下一个已经完成的连接,如果已完成的连接为空,则进程进入睡眠状态(阻塞)。
|
|
若出错返回-1;如果accept成功,返回一个新的socket描述符。其代表与所返回的客户端之间的TCP连接,它是一个连接套接字,之后服务端接收和发送数据都将使用这个描述符进行操作.
在accept的时候,我们常会遇到Invalid argument的错误,出现这个错误的原因有很多,主要是在accept之前的准备工作出了问题。
以上三步有一步出问题或者漏掉一步都有可能出现Invalid argument错误。
我们知道,关闭文件描述符我可使用close函数,同样的close函数也能用来关闭socket文件描述符。12int close(int sockfd);
通常情况下,close一个TCP套接字只是将该socket描述符标记为不可用,这个时候其将不能作为read和write的第一个参数进行数据的发送和接收,然而TCP尝试发送已经排队等待的所有需要发送到对端的数据,发送完毕之后将执行正常的TCP连接终止流程关闭TCP连接.
在各种计算机体系中,对于字节,字等的存储机制有所不同,但是在网络通信过程中,如果双方交流的信息存储结构不一致,则会导致通信失败的结果。当前计算机中通常采用的字节存储机制主要有两种:大端规则与小端规则。网络通信的过程中的存储机制统一为大端规则。
参考:http://www.cppblog.com/tx7do/archive/2015/12/14/71276.html
大多数的套接字函数都使用到了套接字地址,它们以套接字地址的指针作为参数。每个协议族都定义了自己的套接字地址结构,这些套接字地址结构均以sockaddr_开头,以协议族唯一的后缀结尾。
IPv4的套接字以sockaddr_in命名,其具体定义如下:1234567891011121314struct in_addr { in_addr_t s_addr;};struct sockaddr_in { uint8 sin_len; //套接字的长度,sizeof(struct sockaddr_in) sa_family_t sin_family; //协议族 in_port_t sin_port; //套接字端口 struct in_addr sin_addr; //套接字地址 char sin_zero[8]; //保留位}
注意:套接字地址结构仅在本机上使用,虽然结构中的某些字段用在不同主机之间的通信,但是结构体本身不在主机之间传递。
网络通信过程中有不同的协议族,通常我们在socket地址的sin_family中指出当前通信使用的协议族,不同协议族对应不同的参数,其对应参数如下所示:
| sin_family | 协议说明 |
|---|---|
| AF_INET | IPv4协议 |
| AF_INET6 | IPv6协议 |
| AF_LOCAL | Unix域协议 |
| AF_ROUTE | 路由套接字协议 |
| AF_KEY | 密钥套接字 |
套接字函数以套接字地址结构指针作为参数的过程中,由于在C中没有继承的机制,这个时候向套接字函数传递参数的时候,由于不同协议的套接字地址不同,会出现问题。这个时候有一种解决办法就是传递void*指针给socket函数,但是void空指针的出现在socket函数之后,所以这个方案不可行。这个时候的解决方案是 定义一个通用的套接字函数,socket函数的参数为通用套接字地址的指针,传递参数的时候我们将特定的套接字指针强制转换为通用套接字地址指针。 如bind函数的函数原型为:1int bind(int, struct sockaddr*, socklen_t);
通用套接字地址的定义如下:
|
|
Ubuntu16.04中sockaddr_in的定义在/usr/include/netinet/in.h,注意其不支持sin_len字段,为了保持与通用套接字字符串兼容,其保留字符串的长度直接用通用套接字的大小减去其他字段。
|
|
在进行Unix编程的过程中,我们不可避免的会遇到需要时间相关的操作,如文件的创建修改时间,数据库中字段插入或更新的时间。
time_t是一个有符号的整数类型,表示的含义是从1970年1月1日到某一个时间点的秒数。若为32位系统,由int类型的范围可以推算出,time_t可以表示的时间范围是1901-12-13 20:45:52到2038-01-19 03:14:07。
time_b结构体是一个精确到毫秒的结构体,其有四个成员,成员列表如下:123456struct timeb{ time_t time; unsigned short millitm; short timezone; //时区标志 short dstflag; //夏令时标志};
可以通过下列函数获取当前的timeb:1int ftime(struct timeb* tb);
timeval是一个精确到微妙的结构体。其中主要包含两个成员:1234struct timeval{ time_t tv_sec; suseconds tv_usec;};
此值通常通过gettimeofday获取12int gettimeofday(struct timeval* tv, struct timezone* tz); //timezone参数已废弃,一般设为NULL,
timespec是一个精确到纳秒的结构体。其主要包含两个成员1234struct timespec{ time_t tv_sec; //秒 long tv_nsec; //纳秒}
此结构体一般通过下列函数获取:12long clock_gettime(clockid_t which_clock, struct timespec* tp);
上述参数中which_clock用于标识那种时钟时间,可选值如下
struct tm被称为一种分解时间,日期和时间被分解成多个独立字段。其形式如下:1234567891011struct tm { int tm_sec; //秒 (0-60) int tm_min; //分 (0-59) int tm_hour; //时 (0-23) int tm_mday; //日 (1-31) int tm_mon; //月 (0-11) int tm_year; //年 (1900-) int tm_wday; //一周中的周几(周日为0) int tm_yday; //一年中的第几天。(1月1号为0) int m_isdst; //DST大于0表示为夏令时时间。}
Unix时间相关的函数除了上面已经提到的函数还包括以下函数
|
|
time函数返回当前时间的时间戳,此时间戳为从1970年1月1日到当前时间的时间戳,此值不受时区和夏令时(DST)。此函数的返回值为当前的时间戳,函数参数为time_t指针,当前时间除了返回值之外,还将此时间放入timep中。所以使用time函数时我们将timep设置为NULL即可。
|
|
ctime函数的功能为将time_t转化为打印字符串格式。把一个指向time_t的指针timep传入函数ctime,将返回一个长度为26字节的字符串,包含\0和换行符。ctime进行转换的时候,会考虑时区和夏令时,所以返回的时间字符串为当地时间。返回时间的格式如下:1Wed Jun 8 14:22:34 2011
特别注意返回的字符串是经由静态分配的,若多次调用此函数,之前获取的时间会受影响。SuSv3规定,调用ctime(),gmtime(),localtime()以及asctime()中的任意一个函数,都可能覆盖其他函数返回的结果。
静态分配的意思是这些函数返回的数据都是般存在同一个静态变量中,所以下一次的结果会覆盖上一次的数据。如果需要对之前的数据保存,此时需要将结果拷贝到自己分配的内存中。
### gmtime和localtime
|
|
gmttime和localtime的作用是将time_t值转换为分解时间struct tm类型。他们的主要区别是gmtime转换为对应于UTC的分解时间,而localtime考虑时区和夏令时。
|
|
#### 函数功能
mktime的作用是将一个本地时区的分解时间转化为time_t类型。需要注意的是,mktime可能改变timeptr所指的内容。若分解时间不符合要求,mktime将其自动转换为有效时间。如秒为61,此时会将其变成1并讲分加1。
|
|
asc的功能是将分解时间转化为打印时间,特别注意的是asctime转化的过程中不考虑时区和夏令时,返回的数据也是静态分配的。
|
|
此函数的功能是将分解时间转换为打印时间,并可以指定打印时间的格式为format。不同于ctime和asctime,strftime结果不包含换行符。若返回的字符串超过了maxsize大小,函数返回0指示为转换错误。定义的格式中其格式化字符串可以参考预定义的格式。参考《Linux/Unix系统编程手册.上册》第158页。
C语言宏定义在代码编写中很常见,它常会带来一些很高的性能和很方便的写法,在看Linux源码中sockaddr_in的时候遇到宏定义中##。特地在此记录.
Linux中sockaddr_in的定义在文件/netinet/in.h文件中。具体如下:12345678910111213141516/* Structure describing an Internet socket address. */struct sockaddr_in { __SOCKADDR_COMMON (sin_); in_port_t sin_port; // Port number. struct in_addr sin_addr; // Internet address. // Pad to size of struct sockaddr. unsigned char sin_zero[sizeof (struct sockaddr) - __SOCKADDR_COMMON_SIZE - sizeof (in_port_t) - sizeof (struct in_addr)]; }; sa_family_t sa_prefix##family
从上面可以看出,__SOCKADDR_COMMON的宏定义中出现了##的使用方法。那它在宏定义中的意思是什么呢?
##是一种分隔连接方式。它的作用是先分隔,然后进行强制连接。
在普通的宏定义中,预处理器一般吧空格解释为分段标志,然后进行相应的替换工作。但是这样做的结果是被替换的段之间会出现空格。如果我们不希望这些空格出现,可以使用##来代替空格。
如:12
上述type1(int,c)将被替换为:int name_int_type
上述type2(int,c)将被替换为:int c_int_type
故我们再回去看SOCKADDR_COMMON的宏定义. SOCKADDRCOMMON (sin);将被解释为sa_family_t sin_family;
|
|
在宏定义中,#符号的作用是将宏定义参数用””括起来,12example(123 456); //printf("%s", "123 456");
在宏定义中我们可以使用字母或者单词作为占位符,初次之外,我们也可以使用_1,_2作为占位符,不要被它蒙骗了,其作用与单词作为占位符相同。如:
|
从上一节protobuffer的介绍中我们知道字符串类型在protobuffer中有string和bytes两种类型,那这两种类型有什么区别呢,什么时候用string,什么时候用bytes。在C++中两种类型分别对应的是什么类型.下面将揭开迷雾
按照经验我们知道bytes一般适用于存储二进制数据的,但在C++中,string既可以存储ASCII文本字符串,也能存储任意多个\0的二进制序列,那两者的区别在哪里呢?
[libprotobuf ERROR google/protobuf/wire_format.cc:1091] String field ‘str’ contains invalid UTF-8 data when serializing a protocol buffer. Use the ‘bytes’ type if you intend to send raw bytes.
###出现上述错误的原因
这里从ProtoBuf的源码进行分析。protoBuf在序列化的过程中,都会调用SerializeFieldWithCachedSizes这个函数。我们看一下序列化string和bytes在序列化过程中的区别。
对于string类型:1234567891011case FieldDescriptor::TYPE_STRING: { string scratch; const string& value = field->is_repeated() ? message_reflection->GetRepeatedStringReference( message, field, j, &scratch) : message_reflection->GetStringReference(message, field, &scratch); VerifyUTF8StringNamedField(value.data(), value.length(), SERIALIZE, field->name().c_str()); WireFormatLite::WriteString(field->number(), value, output); break;}
对于bytes类型:123456789case FieldDescriptor::TYPE_BYTES: { string scratch; const string& value = field->is_repeated() ? message_reflection->GetRepeatedStringReference( message, field, j, &scratch) : message_reflection->GetStringReference(message, field, &scratch); WireFormatLite::WriteBytes(field->number(), value, output); break;}
从上面可以看到,序列化string和bytes的区别主要在于:string类型序列化调用了VerifyUTF8StringNamedField函数检验string中是否有非法的UTF-8字符。其中VerifyUTF8StringNamedField实现如下:1234567891011121314151617181920212223242526void WireFormat::VerifyUTF8StringFallback(const char* data, int size, Operation op, const char* field_name) { if (!IsStructurallyValidUTF8(data, size)) { const char* operation_str = NULL; switch (op) { case PARSE: operation_str = "parsing"; break; case SERIALIZE: operation_str = "serializing"; break; // no default case: have the compiler warn if a case is not covered. } string quoted_field_name = ""; if (field_name != NULL) { quoted_field_name = StringPrintf(" '%s'", field_name); } // no space below to avoid double space when the field name is missing. GOOGLE_LOG(ERROR) << "String field" << quoted_field_name << " contains invalid " << "UTF-8 data when " << operation_str << " a protocol " << "buffer. Use the 'bytes' type if you intend to send raw " << "bytes. "; }}
protobuf类型在C++和java中的类型对应如下:
为什么bytes类型可以描述string类型,还需要string呢?
根据论坛上说的,string类型在Java中有较多的API可供使用,而bytes较少,所以能定义为string的尽量定义为string,如果字段值确定或者可能含有非法的utf-8编码,则使用bytes类型。
标准的C/C++库不支持正则表达式。在Posix函数库中包含了
## 正则表达式匹配框架
标准的正则表达式匹配框架:
|
|
编译成功返回0,否则返回非0
|
|
0表示匹配成功,1表示REG_NOMATCH。
|
|
|
|
|
|
参考资料:
author.bio
Tencent